[1] 빅데이터의 이해
1. 빅데이터 정의 :
- 빅데이터(Big data) : 큰(big) 데이터 (10TB = 일반적 빅데이터 크기)
- 빅데이터 현상은 다양한 영역에서 일어나고 있으며 정의 또한 다양
- 3V : 빅데이터로 인한 새로운 도전과 기회를 요약(가트너그룹)
2. 빅데이터를 보는 관점의 범위에 따른 정의
- 3V로 요약되는 데이터 자체의 특성 변화에 초점을 맞춘 좁은 범위의 정의
- 데이터 자체뿐 아니라 처리, 분석 기술적 변화까지 포함하는 중간 범위의 정의
- 인재, 조직 변화까지 포함해 빅데이터를 넓은 관점으로 정의하는 방식
3. 빅데이터 출현 배경
1) 패러다임 전환
: 빅데이터 현상은 없었던 것이 새로 등장한 것이 아니라 기존의 데이터, 처리방식, 다루는 사람과 조직 차원에서 일어나는 변화를 가리킴
2) 빅데이터 출현 배경
- 산업계 : 고객데이터 축적(양질 전환 법칙)
- 학계 : 거대 데이터 활용 과학 확산
- 관련 기술 발전 (디지털화, 저장기술, 인터넷보급, 모바일혁명, 클라우드 컴퓨팅)
4. 빅데이터 기능
- 산업혁명의 석탄, 철
- 21세기의 원유
- 렌즈 ex) 구글 'Ngram Viewer'
- 플랫폼
⇒ 차세대 산업 혁신에 꼭 필요한 요소
(차세대 산업혁신에서 원재료 역할을 하면서 그 재료부터 가치를 추출하는 기법까지 아우르는 개념으로 폭넓게 쓰이고 일상생활 깊이 침투할 것)
5. 빅데이터가 만들어 내는 본질적인 변화
1) 사전처리 → 사후처리
: 정해진 특정한 정보만 처리하는 것이 아닌, 가능한 많은 데이터를 모으고
그 데이터를 다양한 방식으로 조합해 숨은 정보를 찾아냄
* 데이터 전처리
데이터를 데이터프레임 구조로 만들어야 한다.
(통계에서는 변수라고 하고 컴공에서는 레이블이라고 하는 컬럼이 붙어있다.)
데이터들이 데이터 프레임 구조로 되어있지 않으면 분석이 어려우므로, 우선 그렇게 바꿔야 한다.
전처리에 시간을 많이 쓰게되므로, 애초에 DBMS 구축에 신경써야한다.
2) 표본조사 → 전수조사
: 샘플링이 주지 못하는 패턴이나 정보를 얻을 수 있는 전수조사(complete enumeration)로 변화.
활용의 융통성 유지가능.
3) 질 → 양
: 대세에 영향을 주지 못하는 사례들일지라도
다른 변수에 대해서는 풍부한 정보를 갖고 있기 때문에
모든 데이터를 활용할 때 훨씬 더 많은 가치를 추출할 수 있다는 관점
4) 인과관계 → 상관관계
: 데이터 기반의 상관관계 분석이 주는 인사이트가 인과관계에 의해 미래 예측을 점점 더 압도해 가는 시대 도래
(인과관계는 기본적으로 상관관계에서 유래하는 것)
6. 빅데이터의 가치 (특정 데이터의 가치를 측정하는 것은 쉽지 않음)
- 데이터 활용 방식 : 재사용, 재조합(mashup), 다목적용 개발
‧ 재사용이나 재조합, 다목적용 데이터 개발 등이 일반화되면서 특정 데이터를 언제·어디서·누가 활용할지 알 수 없음
- 새로운 가치 창출 : 데이터가 기존에 없던 가치를 창출함에 따라 가치 측정이 어려움
- 분석 기술 발전 : 클라우드 분산 컴퓨팅과 새로운 분석 기법의 등장으로 가치 없는 데이터도 거대한 가치를 만들어내는 재료가 될 가능성이 높아짐
7. 빅데이터의 영향
1) 빅데이터가 가치를 만들어 내는 방식(빅데이터 보고서, 2011, 맥킨지)
- 투명성 제고로 연구개발 및 관리 효율성 제고
- 시뮬레이션을 통한 수요 포착 및 주요 변수 탐색으로 경쟁력 강화
- 고객 세분화 및 맞춤 서비스 제공
- 알고리즘을 활용한 의사결정 보조 혹은 대체
- 비즈니스 모델과 제품, 서비스의 혁신 등
2) 빅데이터가 시장에 미치는 영향 ⇒ 생활전반이 스마트화
- 기업 : 혁신과 경쟁력, 생산성 향상
- 정부 : 환경 탐색, 상황분석, 미래대응
- 개인 : 목적에 따라 활용
참고 : https://www.yna.co.kr/view/MYH20161205015500797
[2] 비즈니스 모델
1. 빅데이터 활용 사례
- 기업혁신 사례: 구글 검색 기능, 월마트 매출 향상, 질병 예후 진단 등 의료분야에 접목
- 정부 활용 사례: 실시간 교통정보수집, 기후정보, 각종 지질활동 등에 활용, 국가안전 확보 활동 및 의료와 교육 개선에 활용 방안 모색
- 개인 활용 사례: 정치인과 가수의 SNS 활용
2. 빅데이터 활용 기본 테크닉
1) 연관규칙 학습(Association rule learning)
: 어떤 변인들 간에 주목할 만한 상관관계가 있는지를 찾아내는 방법
ex) A를 구매한 사람이 B를 더 많이 사는가?
2) 유형분석(Classification tree analysis)
: 새로운 사건이 속하게 될 범주를 찾아내는 일
ex) 이 사용자가 어떤 특성을 가진 집단에 속하는가?
3) 유전 알고리즘 (Genetic algorithms)
: 최적화가 필요한 문제의 해결책을 자연선택, 돌연변이 등과 같은 메커니즘을 통해 점진적으로 진화시켜 나가는 방법
ex) 최대의 시청률을 얻으려면 어떤 프로그램을 어떤 시간대에 방송
4) 기계 학습 (Machine learning)
: 훈련 데이터로부터 학습한 알려진 특성을 활용해 '예측'하는 데 초점
ex) 기존 시청기록을 바탕으로 시청자는 보유한 영화중 어떤 영화를 가장 보고 싶어 하는가?
5) 회귀분석 (Regression analysis)
: 독립변수를 조작하며, 종속변수가 어떻게 변하는지를 보며 두 변인의 관계를 파악
ex) 구매자의 나이가 구매 차량의 타입에 어떤 영향을 미치는가?
6) 감정분석 (Sentiment analysis)
: 특정 주제에 대해 말하거나 글을 쓴 사람의 감정을 분석
ex) 새로운 환불 정책에 대한 고객의 평가는 어떤가?
7) 소셜 네트워크 분석 (Social network analysis)
: 오피니언 리더, 즉 영향력있는 사람을 찾아낼 수 있으며, 고객들 간 소셜 관계를 파악
ex) 특정인과 다른 사람이 몇 촌 정도의 관계인가?
* 페이스북은 현재 막힌 상태
3. 위기요인과 통제방안
1) 위기요인
- 사생활 침해 : 데이터 수집이 신속 용이하고, 양이 증대됨에 따라 개인의 사생활 침해 위협뿐만 아니라 범위가 사회·경제적 위협으로 변형될 수 있음. 익명화 기술이 발전되고 있으나, 아직도 충분치 않음. 정보가 오용될 때 위협의 크기는 막대함
- 책임원칙 훼손 : 빅데이터 기반 분석과 예측 기술이 발전하면서 정확도가 증가한 만큼, 분석 대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성도 높아짐
→ 빅데이터 시스템에 의해 부당하게 피해 보는 상황을 최소화할 장치마련이 반드시 필요
- 데이터 오용 : 데이터 과신, 잘못된 지표의 사용으로 인한 잘못된
인사이트를 얻어 비즈니스에 적용할 경우 직접 손실 발생
(참고) 위기와 통제방안 (Enemy of State, 1998)
NORA (Non-Obvious Relationship Awareness)
2) 통제방안
- 동의에서 책임으로 개인정보 제공자의 동의’를 통해 해결하기보다 '개인정보 사용자의 책임'으로 해결
- 결과 기반 책임 원칙 고수 : 특정인의 ‘성향’에 따라 처벌하는 것이 아닌 ‘행동 결과’를 보고 처벌
- 알고리즘 접근 허용 : 알고리즘 접근권 보장 및 알고리즘에 의한 불이익을 당한 사람들을 대변해 피해자를 구제할 수 있는 능력을 가진 전문가로서, 컴퓨터와 수학, 통계학이나 비즈니스에 두루 깊은 지식을 갖춘 ‘알고리즈미스트’ 대두
[3] 상관관계 분석
1. 데이터 분석의 단계
데이터 수집, 저장, 분석, 결과해석 → 인사이트
2. 상관관계 분석
: 덕선이 남편 구하기 (호감도 분석)
목적 : 덕선이와 호감도가 높은 사람을 찾는 것!
1) 엑셀 데이터 분석
- 호감도 설문조사 데이터 수집 (1-7점)
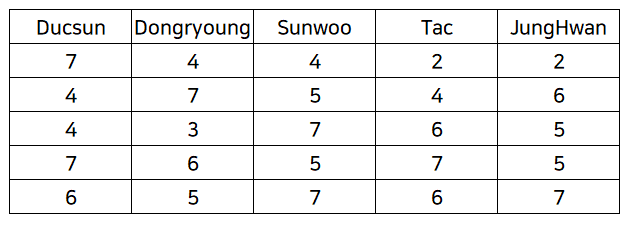
- 상관관계 분석
(데이터 > 데이터분석 > 상관분석)

- 분석 결과
덕선이를 기준으로는 호감도가 있는 사람이 없음.
상관계수 수치가 가장 높은 두명 : 선우, 정환 (0.69...) → 69%의 정의 상관관계가 있다.
상관계수 수치가 가장 낮은 두명 : 선우, 덕선 (-0.46...)
다른 변수들과의 역학관계에 의해 이런 결과가 나오는 것이다.
- insight
만남 1순위 선우/정환
만남 2순위 택이/정환
만남 3순위 선우/택이
만남 4순위 동룡/정환
만남 5순위 택이/동룡
→ 이렇게 만난다면 결혼 성사율이 높아질 것이다.
→ 이걸 이용해 BM을 만든다면? 결혼, 데이트 매칭 서비스
2) R 데이터 분석
install.packages("xlsx")
install.packages("corrplot") #상관관계 시각화
library(xlsx)
setwd("C:/Users/Documents") #엑셀파일이 있는 경로로 지정
xlsx_ds=read.xlsx("dsdata.xlsx",1)
xlsx_ds
dscorr <- cor(xlsx_ds)
library(corrplot)
corrplot(dscorr, method = "number")
corrplot(dscorr, method = "circle")
corrplot(dscorr, method = "pie")
corrplot(dscorr, method = "ellipse")
'🤖 Education > 2020AI BM과정(nipa)' 카테고리의 다른 글
| [AI_BM과정] 8일차 : SVM / kNN (0) | 2020.05.20 |
|---|---|
| [AI_BM과정] 7일차 : LogisticRegression & Decision Tree & 인공신경망 (0) | 2020.05.19 |
| [AI_BM과정] 6일차 : CNN (0) | 2020.05.18 |
| [AI_BM과정] 5일차 : AI 영상처리 (Tensorflow/Linear Regression) (0) | 2020.05.17 |
| [AI_BM과정] 3일차 : 자연어처리 (빈도분석/감성분석) (0) | 2020.05.17 |